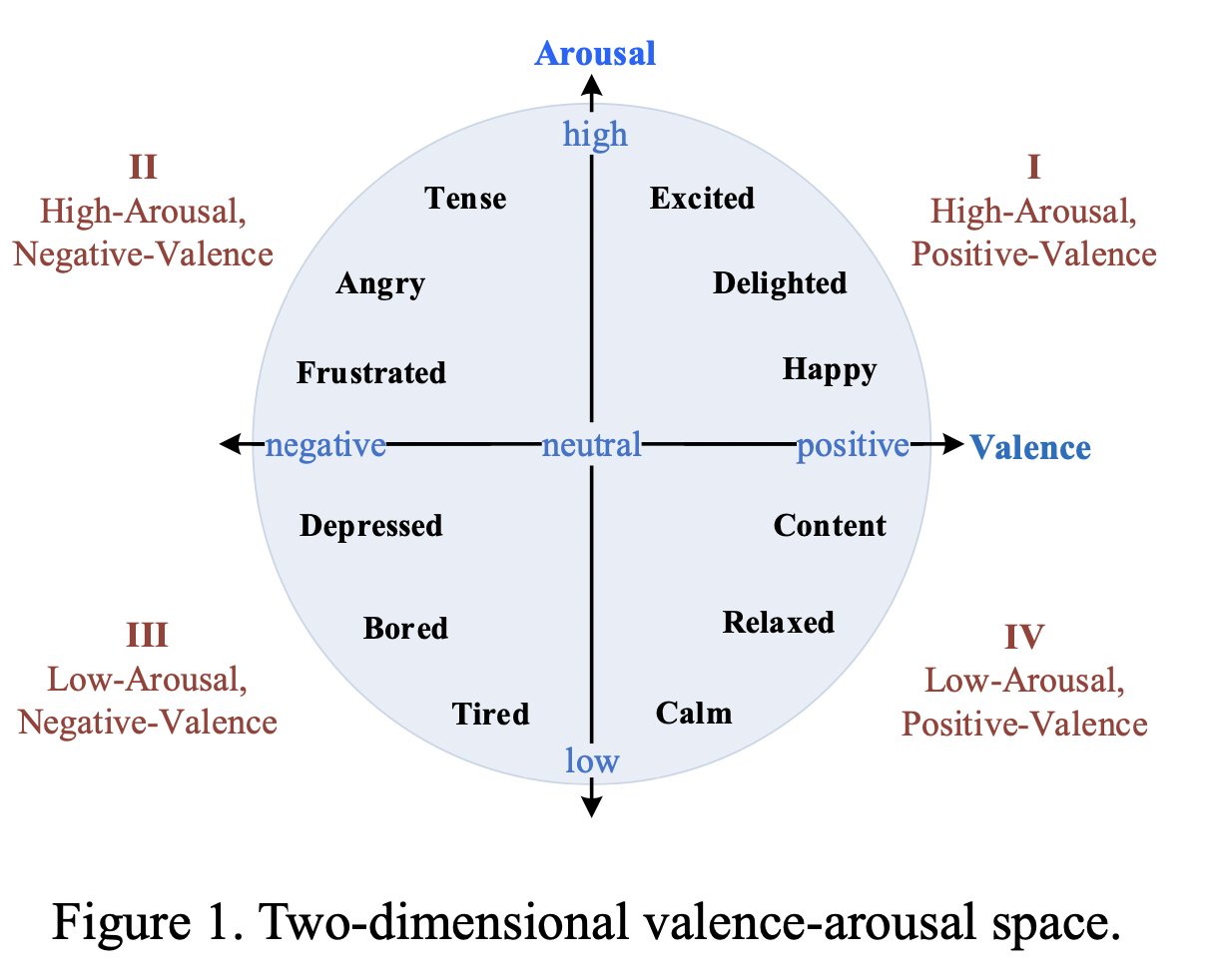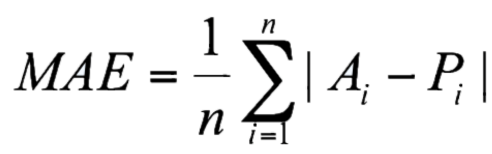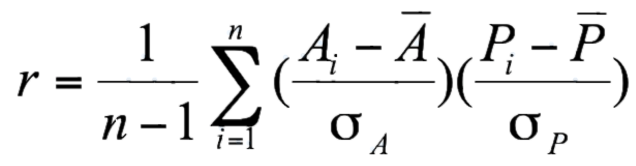
ROCLING 2021 is the 33rd annual Conference on Computational Linguistics and Speech Processing in Taiwan sponsored by the Association for Computational Linguistics and Chinese Language Processing (ACLCLP).The conference will be held in the Engineering Building 5 of National Central University (NCU) in Taoyuan, Taiwan during October 15-16, 2021.
ROCLING 2021 will provide an international forum for researchers and industry practitioners to share their new ideas, original research results and practical development experiences from all language and speech research areas, including computational linguistics, information understanding, and signal processing. ROCLING 2021 will feature oral papers, posters, tutorials, special sessions and shared tasks.
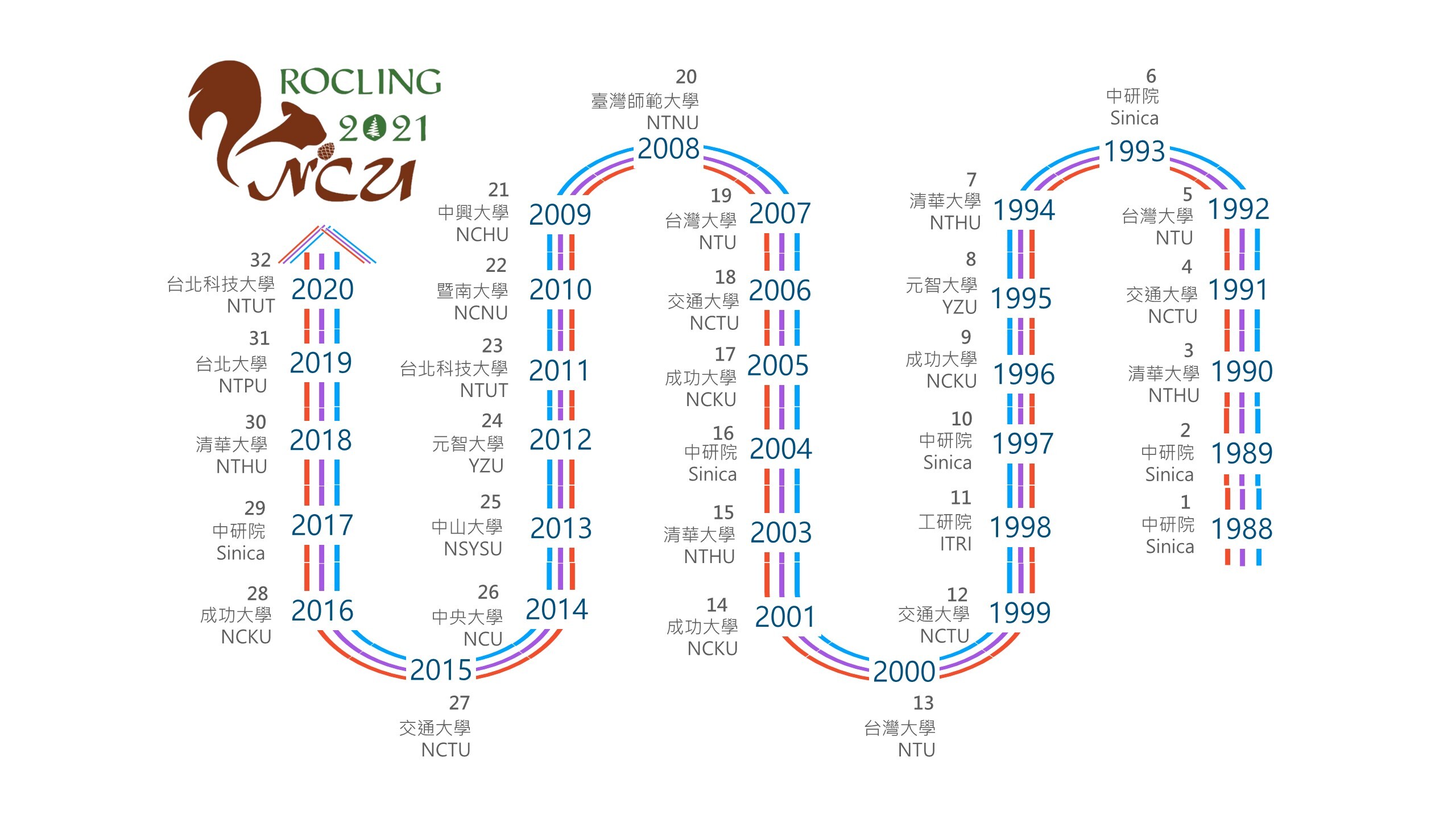
The conference on Computational Linguistics and Speech Processing (ROCLING) was initiated in 1988 by the Association for Computational Linguistics and Chinese Language Processing (ACLCLP) with the major goal to provide a platform for researchers and professionals from around the world to share their experiences related to natural language processing and speech processing. Following are a list of past ROCLING conferences.